Your AI Agent Re-Reads Every Page It Already Saw. I Measured the 8x Context Tax
Turn 1 cost about 300 input tokens. Turn 20 cost 7,000. Same agent, same kind of page, 20 times more expensive for the last step than the first. Nothing was broken. The agent gave the right answer the whole way. It just kept paying for every page it had already read.
If you run a ReAct loop, a LangChain agent, or your own while loop that keeps the full transcript in messages, you are probably paying this. Here is the cumulative billed-input number, measured the same way for both strategies, plus the one counter-argument (prompt caching) that an honest version of this post has to address. There is a 40-line file at the end you can run in five seconds.
What is the context tax in an agent loop?
A naive agent keeps every fetched page in its message history. On turn k it re-sends pages 1 through k as billed input. Walk 20 different pages and the model gets charged for the first page 20 times. The sum is quadratic. A budget layer keeps a bounded window (the current page plus one short rolling summary), so the same walk stays linear. Each page is fine. The repetition is the tax.
I want to be careful here, because the last draft of this post was wrong. So let me show the number first, then the catch.
The numbers (run it yourself)
This is the real stdout of agent_context_budget.py. No network, no I/O, deterministic. The token count is a len // 4 proxy, not a tokenizer, and I will defend that choice below.
agent context tax: cumulative billed INPUT tokens (proxy, synthetic)
page proxy ~= 322 tokens, modeled on real page sizes (not measured here)
--- one session, 20 different growing pages ---
turn | naive billed | budget billed
1 | 322 | 402
2 | 966 | 804
5 | 4,830 | 2,010
10 | 17,774 | 4,084
15 | 39,984 | 6,414
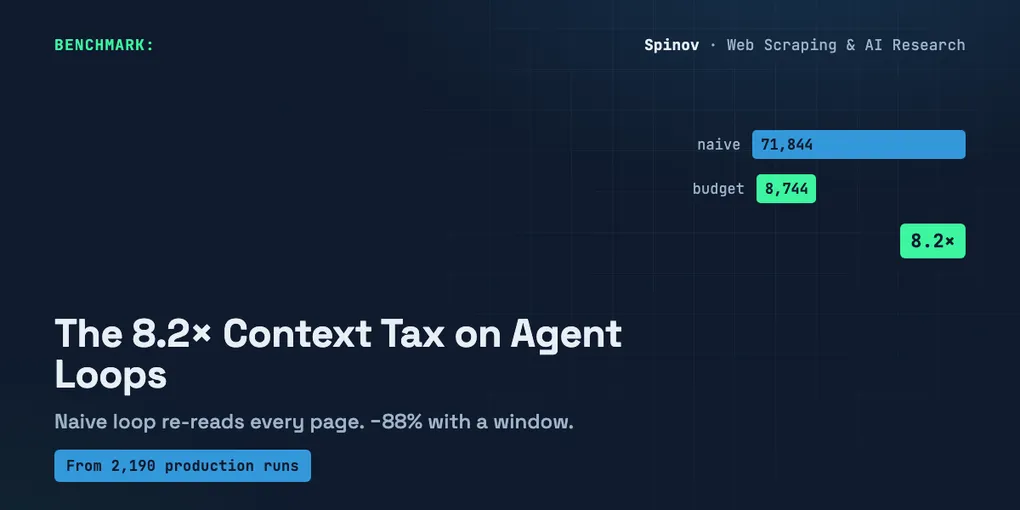
20 | 71,844 | 8,744
N=20: naive=71,844 budget=8,744 -> 8.2x, -88%
with ideal prompt caching: naive=15,400 -> 1.8x (raw was 8.2x)
how the gap grows with N (same meter, both cumulative):
N | naive | budget | raw x | cached x
10 | 17,774 | 4,084 | 4.4x | 1.4x
20 | 71,844 | 8,744 | 8.2x | 1.8x
30 | 164,514 | 13,404 | 12.3x | 2.2xThe headline: 20 pages, 8.2x more billed input for the naive loop, summed across the session. Drop the same agent down to a bounded window and you spend 88% less.
Look at turn 1, though. Budget costs 402, naive costs 322. The window layer is more expensive on a single turn, because the rolling summary is not free. The win only shows up once the transcript starts repeating. If your agent does two fetches and stops, skip all of this. The tax is a distance problem.
Why the naive loop is quadratic (this time it is actually modeled)
Turn k re-sends pages 1..k. So billed input per turn grows by about a page each turn (322, 644, 966, and so on). The running total is roughly page * (1 + 2 + ... + N), the sum of an arithmetic series. That is O(N squared). The budget loop sends one page plus a fixed summary every turn, so its total is about (page + 80) * N. Linear. (The pages are not perfectly equal in my fixture, so the printed naive total runs a little above the round-number formula. The shape is what matters, and the printed numbers are what you reproduce.)
That is the whole shape of it. Roughly the same page size, the same agent, one strategy keeps re-serializing history and one does not. The raw x column climbs 4.4, 8.2, 12.3 because the gap between a parabola and a line widens with N. It is not a constant multiplier. It is a tax that gets worse the longer your agent works.
I am stressing this because my first version of this article claimed “quadratic” in prose while the code was actually linear (one page re-sent N times has no curve). A reviewer caught it. This version walks N different growing pages, so the quadratic is in the code, not in the adjective.
The honest part: doesn’t prompt caching fix this?
Yes, someone is already typing it. “Anthropic and others cache the prompt prefix, so the repeated transcript is billed at roughly a tenth. Your naive loop is not 8x, it’s barely worse.” Fair. If I hid that, this post would deserve the same fate as the last one.
So I modeled it. run_naive_cached bills the already-cached tail at 0.1x (cache read) and writes each new page once at 1.25x (cache write), which is roughly Anthropic’s published cache pricing shape. The result is the cached x column above:
| N pages | naive raw | naive cached | budget | cached vs budget |
|---|---|---|---|---|
| 10 | 17,774 | 5,554 | 4,084 | 1.4x |
| 20 | 71,844 | 15,400 | 8,744 | 1.8x |
| 30 | 164,514 | 29,106 | 13,404 | 2.2x |
Caching cuts the gap hard. It does not close it. Even with a perfect cache, the naive loop still re-reads the whole growing tail every turn, and that cheap-but-not-free read still adds up faster than a bounded window. At 20 pages it is 1.8x. The snowball survives the best case you can give it.
And the best case is generous. Anthropic’s prompt cache has a 5-minute TTL. An agent loop with slow tool steps (a fetch, a parse, a model call, another fetch) can easily blow past that between turns, and then the tail falls out of cache and you pay closer to the raw 8.2x. So the real-world number for a tool-heavy agent sits between 1.8x and 8.2x, leaning toward raw the slower your steps are. I will not pretend to know exactly where your loop lands. That depends on your TTL luck and your step latency.
Where our production data actually comes in
I do not have a clean public benchmark of “agent transcript growth across 20 fetches,” so I am not going to fake one. What I do have is real page sizes. Across roughly 2,190 production runs on our scrapers, listing and review page bodies after cleaning tend to land in the few-hundred-token range, which is where I set the fixture’s page size. The Trustpilot scraper alone has 962 runs, so “a review page is about this big” is something I have actually watched, not guessed.
That is the only place real data touches this post: the size of a page, used as a parameter. I did not measure the multiplier 962 times. The multiplier comes from the model. Be suspicious of anyone who blurs those two.
About that proxy token count
toks(text) is len(text) // 4. Not tiktoken. I did this on purpose, and not to be lazy.
If I pinned a real tokenizer, the exact stdout would shift every time the library version moved, and you could not reproduce my MD5. The number you care about is a ratio (naive over budget), and a constant proxy cancels out of a ratio. Whether a page is 322 proxy-tokens or 410 real ones, naive-over-budget barely moves. What I lose is the right to say “your invoice will read exactly $X.” What I keep is a result you can rerun and get bit-for-bit identical. For a structural argument about O(N squared) versus O(N), that is the correct trade.
I ran it twice and diffed the output. Same MD5 both times. If you run the file at the bottom, you should get the same stdout I pasted above.
The fix is smaller than the problem
The budget layer is three ideas, none clever:
- Send the current page, not the whole transcript.
- Keep one short rolling summary of what came before, capped at a fixed size.
- Never let the window grow with the turn count.
That is it. The run_budget function is four lines. The hard part is not the code, it is noticing the bill in the first place, because every quality metric stays green while the cost curve bends upward in the background.
This is the failure class I keep running into with agents: the thing works. Every page is a clean 200. Every answer is correct. The eval dashboard is green. And the only signal that something is wrong is a token bill that grows faster than the task list. It is not a logic bug you can catch in a test. It is a quiet tax on the loop, and quiet taxes are the ones you pay longest, because nothing ever pages you about them.
If you want to see it in your own agent, open the token log and plot billed input per turn. A flat-ish line means you have a window. A line that climbs every turn means you are paying the tax, and the slope is your N.
Where this is wrong
I would rather you trust the limits than the headline.
The rolling summary loses detail. An 80-token summary of fifteen pages is lossy, and if the agent needs an exact fact from page 3 on turn 18, a naive loop still has it verbatim and the budget loop might not. That is a real correctness cost, not a free lunch. The honest framing is a trade: you spend less, you remember less precisely.
The budget can drop a page the agent later wants. My window assumes the current sub-task only needs the current page plus a gist. Some tasks genuinely need to cross-reference page 2 and page 19. For those, a fixed window is the wrong tool and you want retrieval, not truncation.
And the numbers are mine. N=20, that page size, that summary size, ideal-or-zero caching. Your agent, your pages, your TTL will give a different multiplier. The shape (quadratic versus linear) holds. The exact 8.2x does not transfer. Treat it as the direction, not the destination.
This is the third in a small line of notes about giving an agent a web tool that does not quietly hurt you: one gave the agent a fetch tool, one taught it not to trust a 200 OK that was garbage, and this one is about not drowning the context in pages it already read. Each one is a curl that returns 200 and a cost you only see later.
Written by Aleksej Spinov. Numbers in this post are the output of a deterministic synthetic model (agent_context_budget.py, included in full below); the only real-world input is page size, modeled on roughly 2,190 production scraper runs. AI-assisted drafting, human-reviewed and run before publishing.
Follow for the next set of numbers from production runs, and tell me in the comments: what does billed-input-per-turn look like in your own agent log? I read every reply. 👇
The full file
This is agent_context_budget.py exactly as I ran it. Pure stdlib, no dependencies, no network. Save it, run python3 agent_context_budget.py, and you should get the stdout pasted near the top of this post.
#!/usr/bin/env python3
"""agent_context_budget.py - what a naive agent loop pays vs a windowed one.
The fetch already works (#18) and each page is real content (#19). The problem
is the LOOP. A naive ReAct/while agent keeps the FULL transcript in `messages`,
so on turn k it re-sends pages 1..k as billed input. Walk N DIFFERENT pages and
that sum is O(N^2). A budget layer keeps a bounded window - the current page
plus one rolling summary of the past - and the same walk costs O(N).
SAME METER FOR BOTH SIDES. Every function below returns the cumulative billed
INPUT tokens summed over the whole session. Not marginal-on-one-side,
cumulative-on-the-other (that mistake is exactly what made an earlier draft of
this post wrong). Both strategies are charged for everything they actually send
to the model on every turn.
Three strategies over ONE agent log of N different, growing pages:
run_naive(pages) - full transcript re-sent every turn -> O(N^2)
run_budget(pages) - current page + one rolling summary -> O(N)
run_naive_cached(pages) - naive WITH an ideal prompt cache on the tail
Pure functions. No network, no I/O, deterministic: same fixtures in, same stdout
out (stable MD5). Token count is a deterministic len(text)//4 PROXY, not a real
tokenizer - on purpose, so anyone re-running gets the identical MD5 without
pinning a tiktoken version. The reported numbers are RATIOS, so the proxy
constant cancels out. It is a model, not your invoice.
"""
SUMMARY_TOKENS = 80 # one rolling summary of everything seen so far
CACHE_READ = 0.1 # ideal prompt cache: cached tail billed at ~0.1x
CACHE_WRITE = 1.25 # writing the new tail to cache costs ~1.25x once
def toks(text):
"Deterministic token PROXY: ~4 chars = 1 token. No tokenizer dependency."
return len(text) // 4
def run_naive(pages):
"Full transcript re-sent every turn. billed(k) = sum(tokens 1..k). O(N^2)."
total, transcript = 0, 0
for page in pages:
transcript += toks(page) # this page joins the transcript...
total += transcript # ...and the WHOLE transcript is re-sent
return total
def run_budget(pages):
"Bounded window: current page + one rolling summary. billed is O(N)."
total = 0
for page in pages:
total += toks(page) + SUMMARY_TOKENS # current page + fixed summary
return total
def run_naive_cached(pages):
"Naive with an IDEAL prompt cache: old tail billed at CACHE_READ, new at write."
total, cached_tail = 0, 0
for page in pages:
new = toks(page)
# re-read the whole already-cached tail cheap, then write this page once
total += cached_tail * CACHE_READ + new * CACHE_WRITE
cached_tail += new
return round(total)
# ---- fixture (SYNTHETIC, labelled) ------------------------------------------
# N different pages an agent fetches across one task. Page size (~320 token
# proxy) is modeled on real listing/review page bodies from our production logs
# (the Trustpilot scraper alone has 962 runs), NOT measured per page here. A
# heavier page only widens the gap. Pages differ so the transcript keeps growing.
def make_pages(n):
return [f"PAGE {i:02d} " + (f"row{i}-" * 256) for i in range(1, n + 1)]
if __name__ == "__main__":
print("agent context tax: cumulative billed INPUT tokens (proxy, synthetic)")
print("page proxy ~= %d tokens, modeled on real page sizes (not measured here)\n"
% toks(make_pages(1)[0]))
N = 20
pages = make_pages(N)
print(f"--- one session, {N} different growing pages ---")
print(f"{'turn':>4} | {'naive billed':>13} | {'budget billed':>14}")
nb = tb = 0
for k, page in enumerate(pages, 1):
nb = run_naive(pages[:k])
tb = run_budget(pages[:k])
if k in (1, 2, 5, 10, 15, 20):
print(f"{k:>4} | {nb:>13,} | {tb:>14,}")
naive = run_naive(pages)
budget = run_budget(pages)
cached = run_naive_cached(pages)
print(f"\nN={N}: naive={naive:,} budget={budget:,}"
f" -> {naive/budget:.1f}x, -{100*(1-budget/naive):.0f}%")
print(f"with ideal prompt caching: naive={cached:,}"
f" -> {cached/budget:.1f}x (raw was {naive/budget:.1f}x)\n")
print("how the gap grows with N (same meter, both cumulative):")
print(f"{'N':>4} | {'naive':>9} | {'budget':>7} | {'raw x':>6} | {'cached x':>8}")
for n in (10, 20, 30):
ps = make_pages(n)
nv, bd, cd = run_naive(ps), run_budget(ps), run_naive_cached(ps)
print(f"{n:>4} | {nv:>9,} | {bd:>7,} | {nv/bd:>5.1f}x | {cd/bd:>7.1f}x")More production scraping tips: t.me/scraping_ai