-
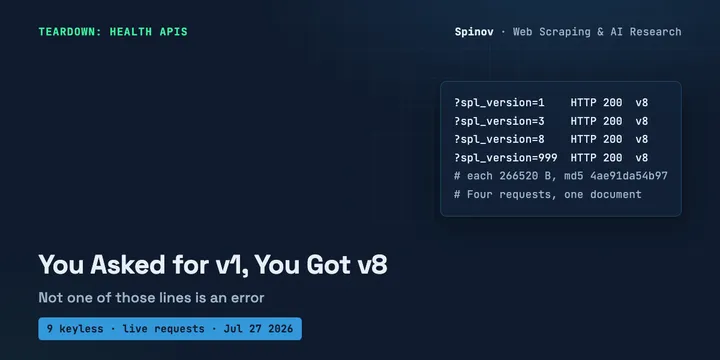
9 Keyless Health APIs: You Asked for v1, You Got v8
-
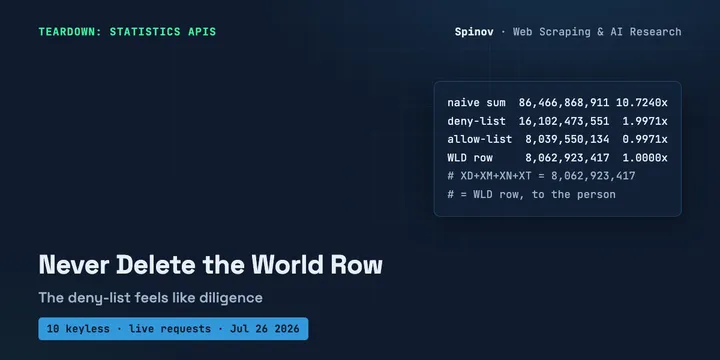
10 Keyless Statistics APIs: Never Delete the World Row
-
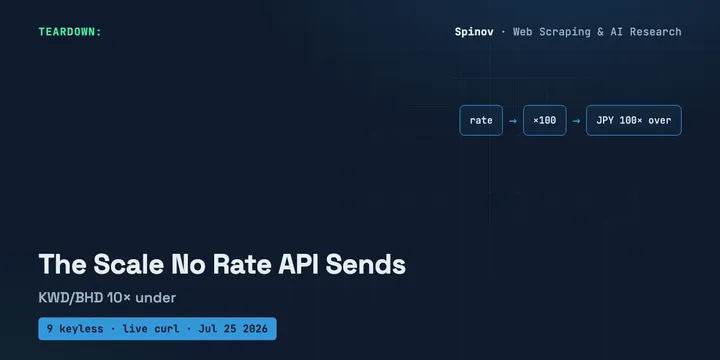
9 Keyless Currency APIs, and the Yen That Breaks Your Cents
-

I Gave 9 Free IP-Geolocation APIs One IP. 3 Pointed to a Farm in Kansas.
-
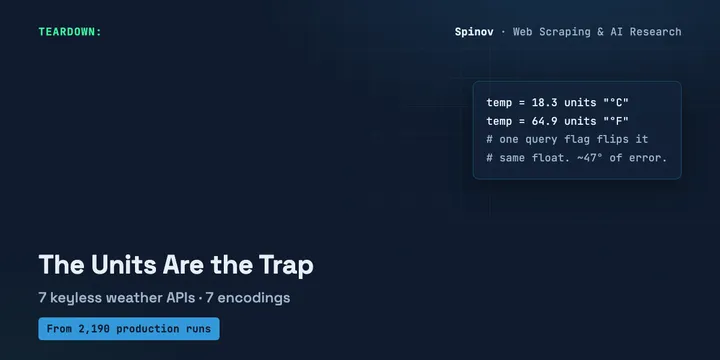
7 No-Key Weather APIs: Finding One Is Easy, the Units Are the Trap
-
11 Keyless Package-Registry APIs, and Why You Can't Pin `latest`
-

16 Keyless DNS and Cert APIs. Only 3 of 12 Answer for Themselves.
-

Your Bot Asked 5 Keyless Crypto APIs for UNI. None Said Which UNI.
-
16 Keyless Game APIs, 5 Incompatible Ways to Say "Empty"
-
Free Sports APIs: I Curl-Tested 15, 8 Need No Key
-
Your Dictionary API 404s on Real Words. Here Are 9 Keyless.
-
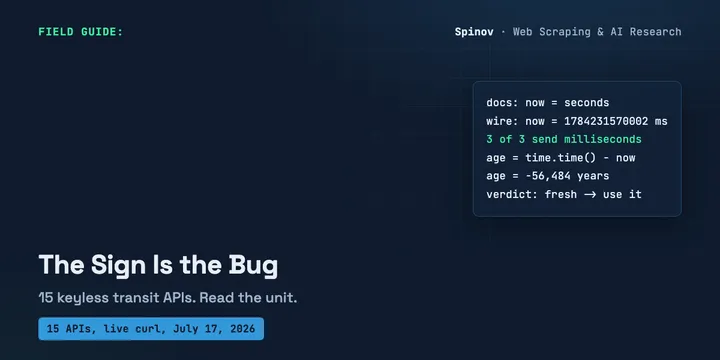
15 Keyless Transit APIs, and a Timestamp Their Own Docs Get Wrong
-
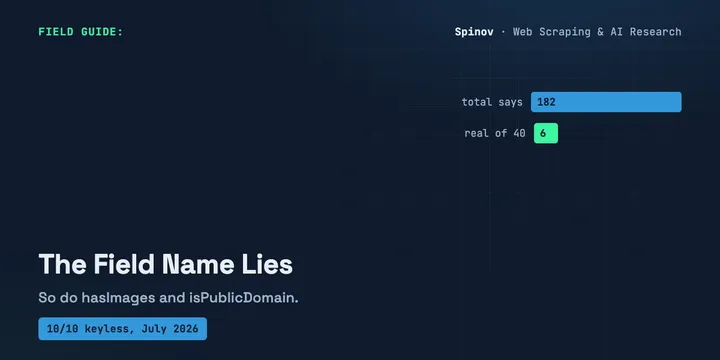
10 Free Art & Museum APIs With No Key (2026)
-

11 Free Space & Astronomy APIs With No Key (2026)
-
11 Free Music APIs With No Key or Signup (2026)
-
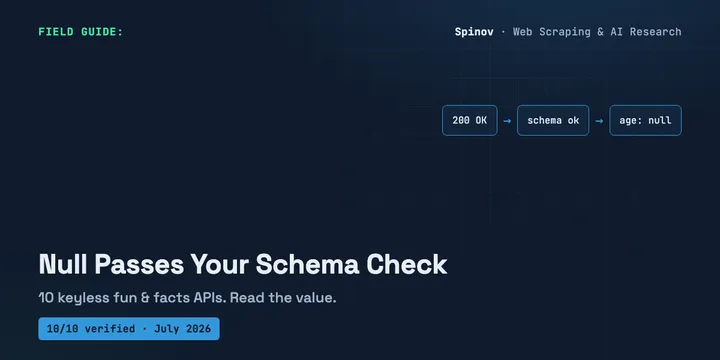
10 Free Facts, Jokes & Name APIs With No Key (2026)
-
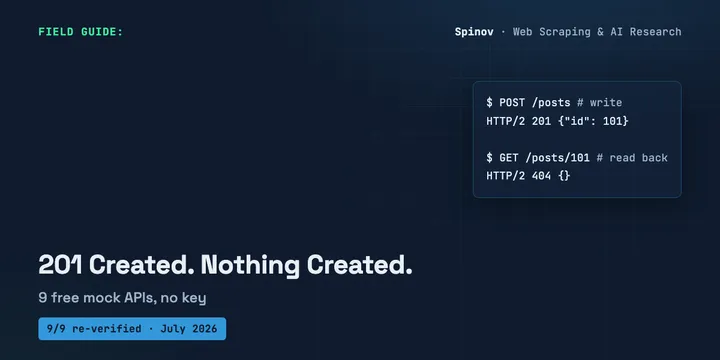
9 Free Mock & Fake-Data APIs With No Key (2026)
-
8 Free Pop-Culture APIs With No Key (2026)
-
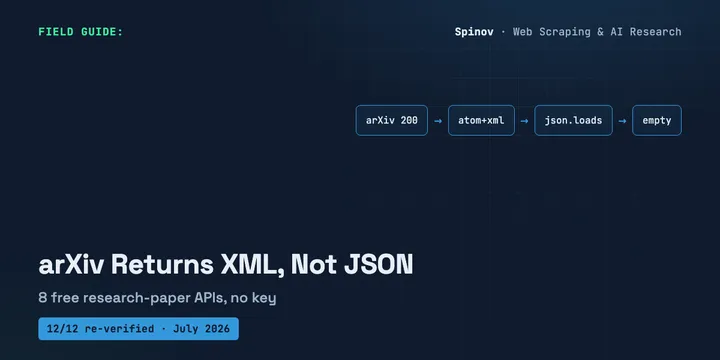
8 Free Research Paper APIs With No Key (2026)
-
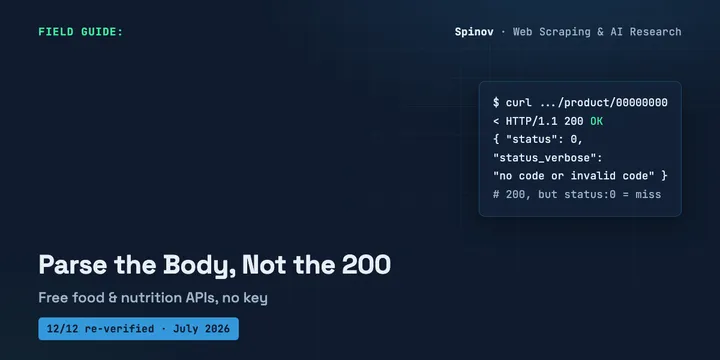
8 Free Food & Nutrition APIs (No Key, Tested 2026)
-

10 Free Government APIs With No Key or Signup (2026)
-
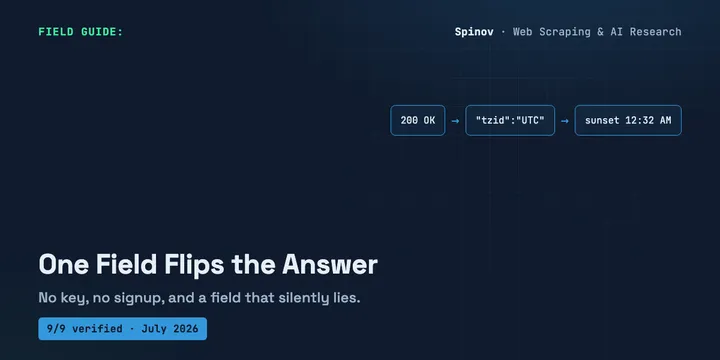
9 Free Public Holiday & Time APIs With No Key (2026)
-
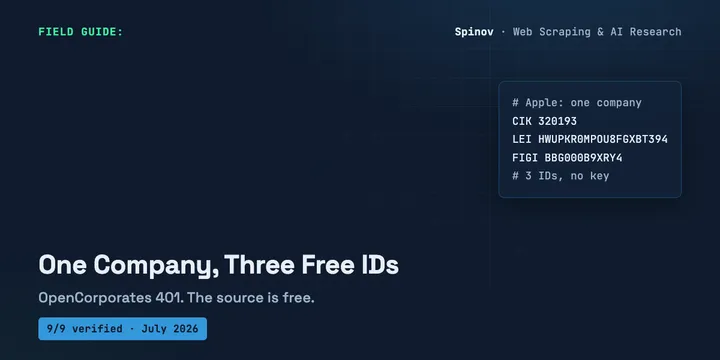
9 Free Company Data APIs With No Key or Signup (2026)
-
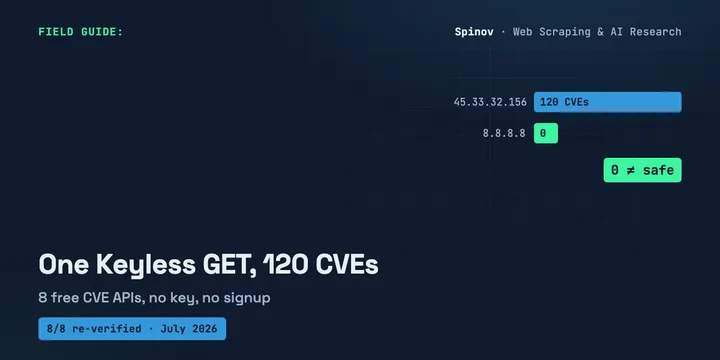
8 Free CVE & Vulnerability APIs With No Key (2026)
-

8 Free Geocoding APIs With No Key and No Signup (2026)
-
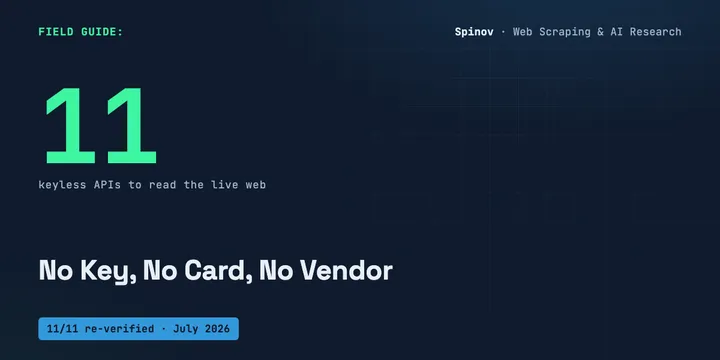
11 Free No-Key APIs Your AI Agent Can Use to Read the Web
-
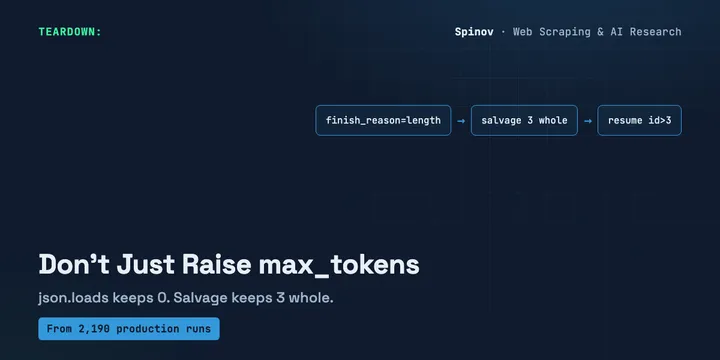
Your LLM JSON Got Cut Off. Don't Just Raise max_tokens
-
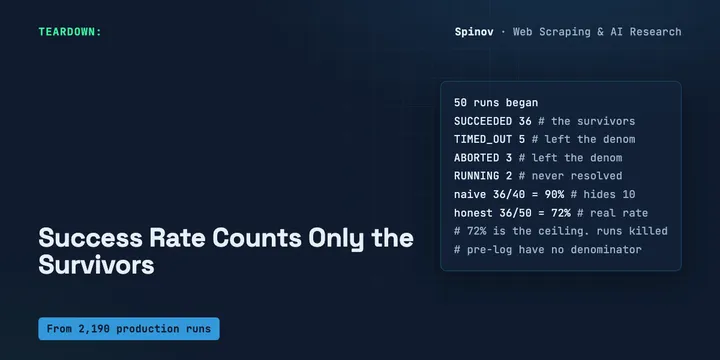
Your Agent Success Rate Counts Only the Survivors
-

RAG Chunking: Overlap=0 Drops Facts on the Boundary
-
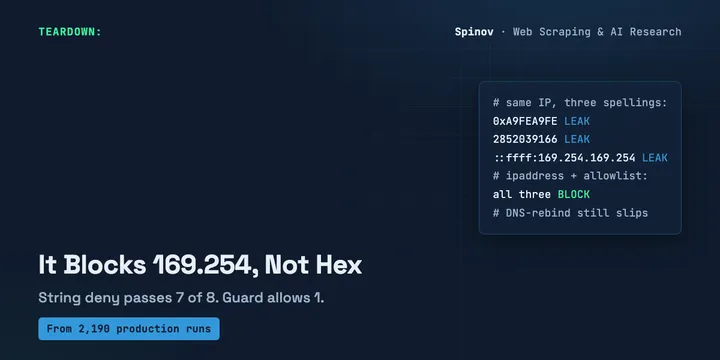
SSRF in AI Agents: Blocking 169.254 by String Isn't Enough
-

Caching LLM Calls: A Raw Prompt Key Almost Never Hits
-
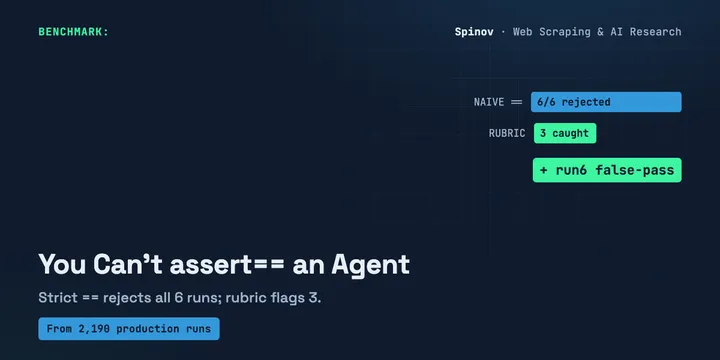
You Can't Unit-Test an AI Agent. You Can Regression-Gate It.
-
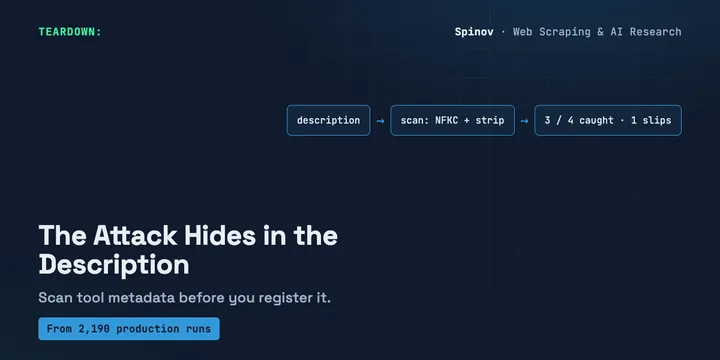
Your Agent Trusts the Tool's Description. The Attack Hides There.
-
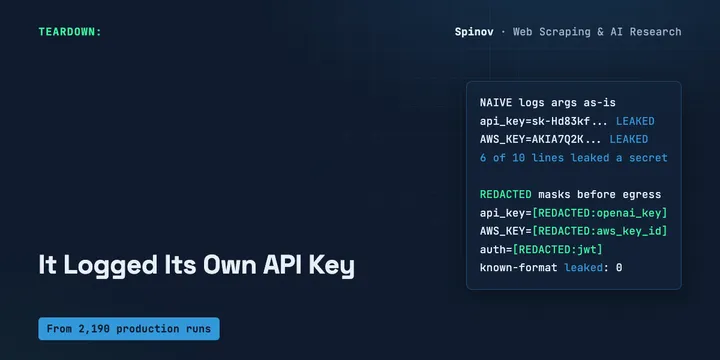
Your AI Agent Logged Its Own API Key. I Wrote the 40-Line Redactor.
-
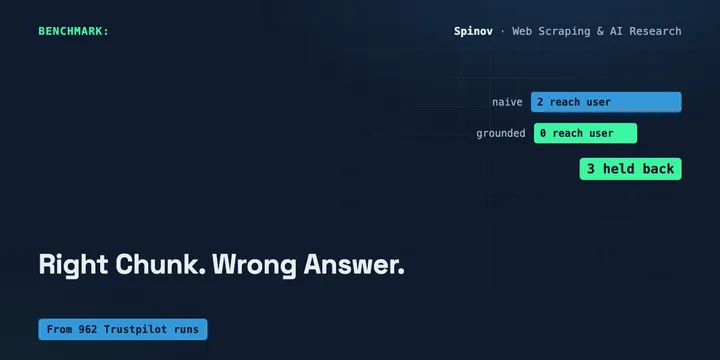
Your RAG Answers Confidently. The Source Doesn't Say That.
-

The MCP Tool Your Agent Calls Changed Its Schema. It Didn't Notice.
-
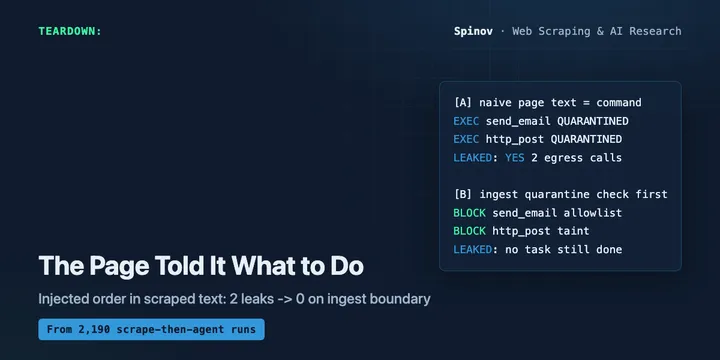
Your AI Agent Scraped a Page. The Page Told It What to Do.
-

Your Agent Doesn't Run Out of Context. It Degrades at 79%
-
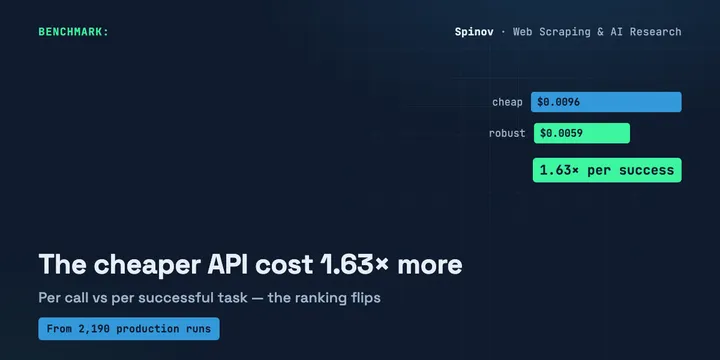
The Cheaper API Was 2.5x Cheaper. It Cost 1.6x More.
-

One Empty 200 OK Poisoned 5 of My Agent's 10 Steps
-
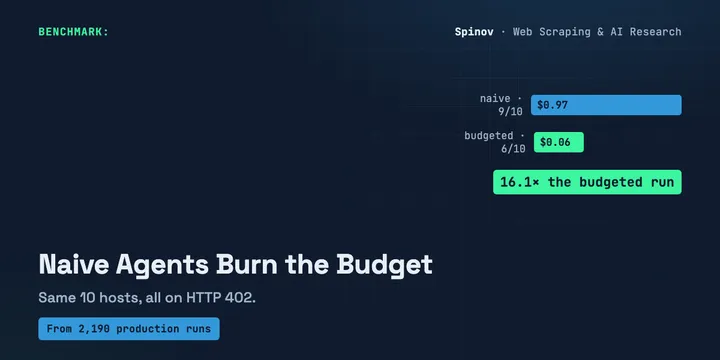
The HTTP Code Your AI Agent Doesn't Handle Yet: 402
-

Your AI Agent Will Double-Charge on a Lost Response
-
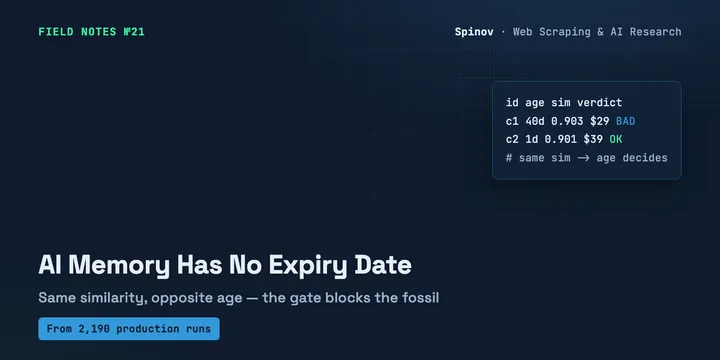
Your AI Agent's Memory Has No Expiry Date: I Scored Freshness on a Real Corpus
-
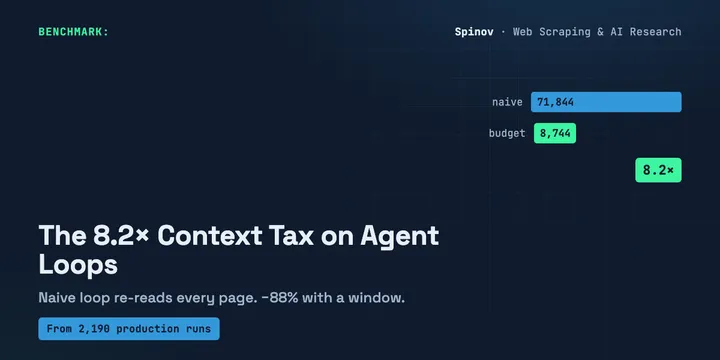
Your AI Agent Re-Reads Every Page It Already Saw. I Measured the 8x Context Tax
-
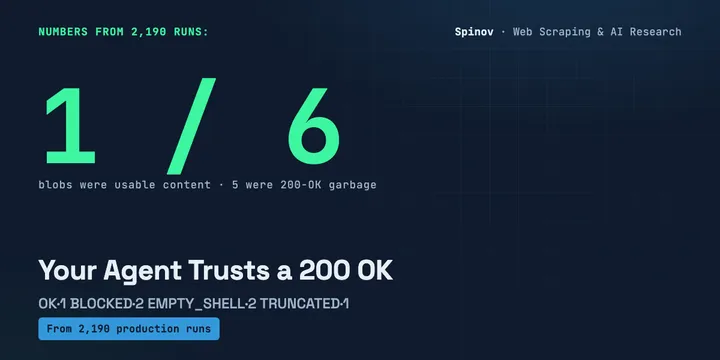
Your AI Agent Trusts a 200 OK. I Logged How Often the Page Was Garbage
-
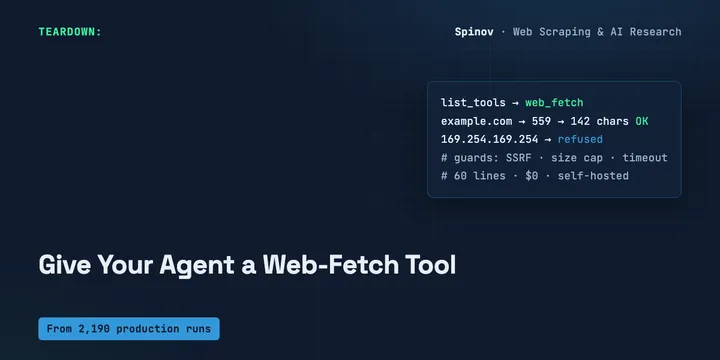
Give Your AI Agent a Web-Fetch Tool: a 60-Line MCP Server (Free, Self-Hosted)
-
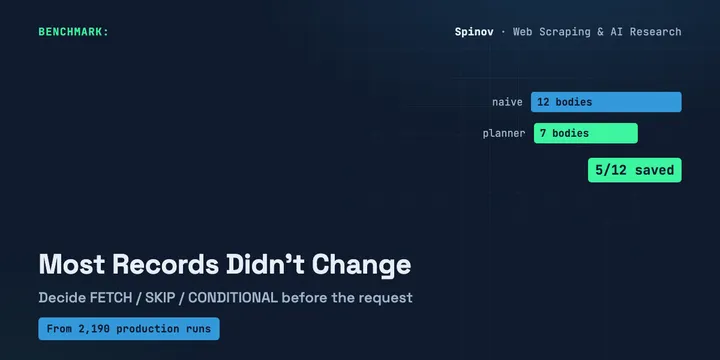
Your Scraper Re-Downloads Everything. Most Didn't Change.
-

Your Scraper Got Clean Data. The Site Lied to It.
-

Your Scraper Passes Every Run. It's Still Rotting.
-
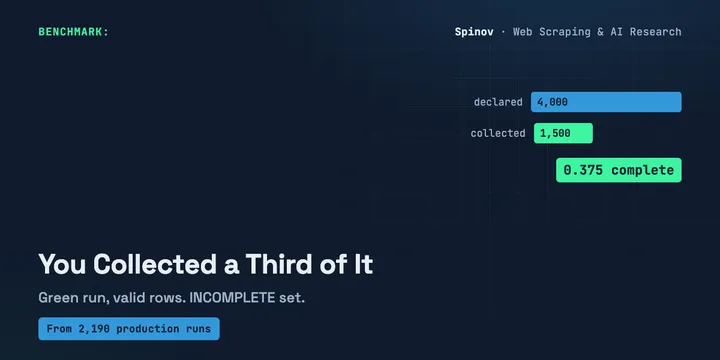
Your Scraper Collected 50 Rows. There Were 4,000.
-
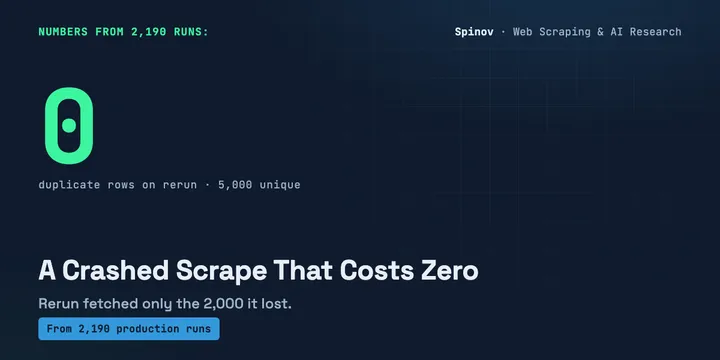
Your Scraper Died at Row 12,000. The Rerun Pattern.
-
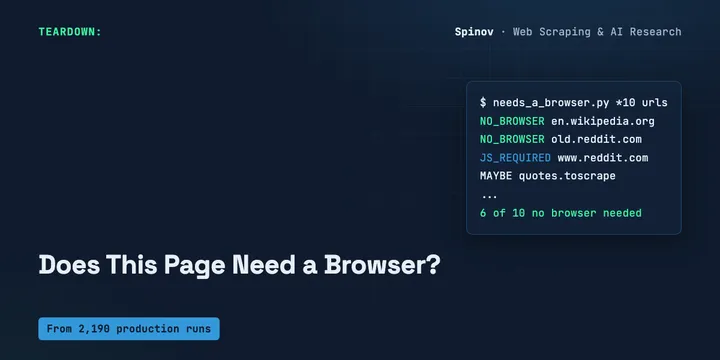
A 30-Line Probe That Tells You If a Page Needs a Browser
-
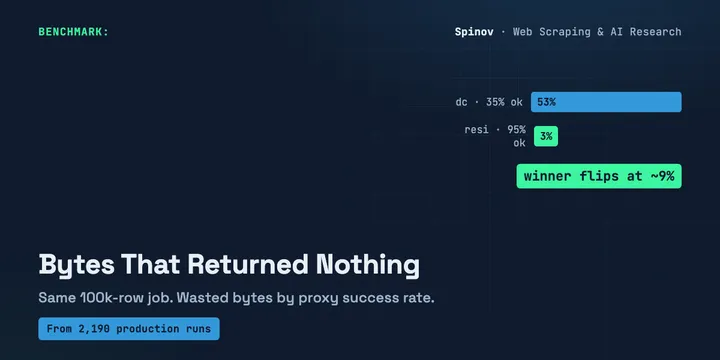
You Pay for the Bandwidth That Returns Nothing
-

A Budget Brake That Stops a Scraper Before $200
-

Spoofing Your Scraper's Fingerprint Is a Losing Arcade
-
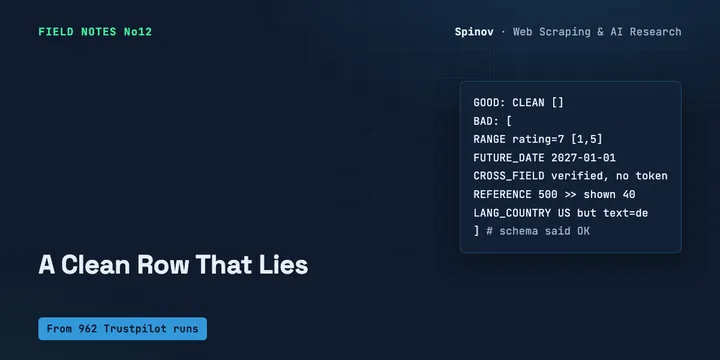
Your Scraper Returned a Clean Row. It Was Wrong.
-
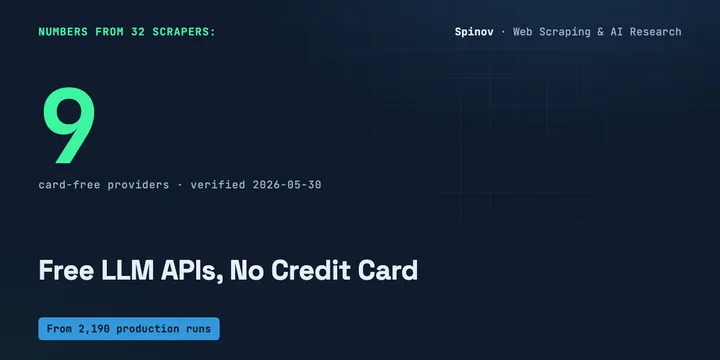
9 Free LLM APIs in 2026 You Can Use Without a Credit Card
-
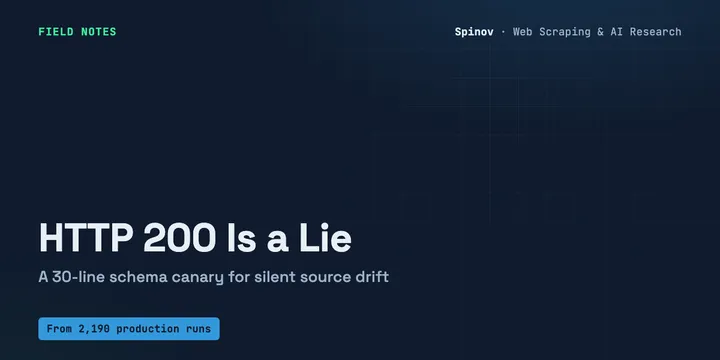
HTTP 200 Is a Lie: A 30-Line Schema Canary for Source Drift
-
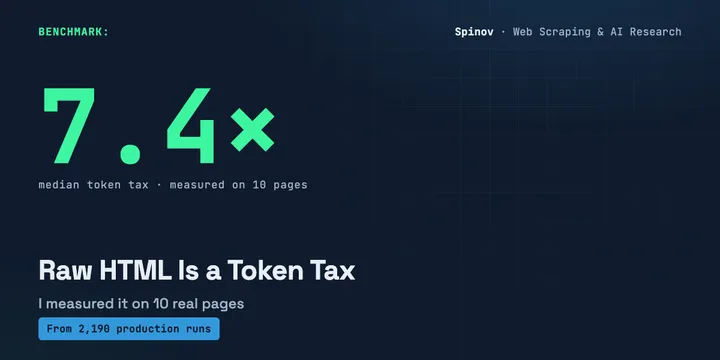
Feeding Raw HTML to Your LLM Is a Token Tax. I Measured It on 10 Real Pages — Median 7.4×, and It Hits Every Scheduled Run
-

I've Run 2,190 Production Scrapes. The Framework You Pick Isn't What Breaks — Here's What Actually Does
-
Scraping All the Text Is the Easy 10%. Keeping the Corpus Worth Training On Is the Other 90% — Notes From 962 Runs
-
I've Run 2,190 Production Scrapes — "Ethical" Isn't a robots.txt Question, It's a Rate-Limit One
-
Conditional GET in production scrapers: what I learned wiring it into 3 actors
-
Three memory-leak patterns in long-running scrapers (and how I caught them after 968 Trustpilot runs)
-
Token Economics of Agent-Driven Scraping: When LLM Agents Cost 50× More Than a Cron Job
-
5 Apify dataset deduplication patterns that stop double-billing your customers
-
5 Apify scheduler mistakes that quietly burn compute units
-
Token Bucket vs Exponential Backoff: What Changed After 966 Runs
-
Building a Proxy Health Monitor for 24/7 Scraper Uptime
-
5 production scraping failures from 1000+ runs (and the fixes that actually shipped)
-
Description drift in serverless function catalogs — a monthly refresh playbook
-
3 Telegram Channels Worth Following for Production Data Engineering
-
I write production scrapers. AI made 30% of them worse. Here's the rule of thumb.
-
5 Apify webhook patterns that turn one-off scrapers into reliable data pipelines
-
5 Apify run-log patterns that make production debugging 10x faster
-
5 Apify Scheduler Mistakes That Quietly Burn Compute Units (And the Cron Fixes)
-
5 Apify run-log patterns that make production debugging 10× faster
-
Five Apify Input Schema Mistakes And The Fixes That Stuck
-
Apify vs. self-hosted: the three numbers I use to decide
-
Cost per result: a 4-line worksheet for Apify actors
-
Dead features in your own code: a self-audit story from my Apify actor
-
DuckDB + dbt: a zero-cost analytics warehouse for projects under 100 GB
-
Idempotent webhook receivers in 50 lines of Python
-
Three operational rules I added after my Trustpilot scraper crossed 100 runs
-
Why your retry logic is broken (and the 30-line fix)
-
Schema drift killed our pipeline — three contract tests that catch it
-
When NOT to scrape: 3 patterns where I now reach for an API instead
-
Automate Your Backups with MinIO: Free S3-Compatible Storage for Everything
-
Traefik + Docker: Zero-Config Reverse Proxy That Discovers Your Containers Automatically
-
How my Trustpilot scraper survived 949 production runs (and the 3 things that almost killed it)
-
Welcome — what this blog is for
-

What 250 runs of a Trustpilot scraper taught me about anti-bot patterns