The HTTP Code Your AI Agent Doesn't Handle Yet: 402
Your fetch agent knows two endings to a request. 200: parse it. 403: back off, rotate, or skip. That branch has been the whole game for years.
There’s a third ending now, and it’s the one your code falls through. 402 Payment Required, with a dollar amount in the header. Cloudflare turned it on for Pay-Per-Crawl in July 2025. 403 punished you with retries — wasted time, nothing you couldn’t see. A bare 402 isn’t a charge by itself; it’s a quote. But the moment your agent does the obvious thing — re-request and agree to the price — it’s an invoice. And here’s the part that bites: by default, your HTTP client has no brake for it.
TL;DR
- Cloudflare Pay-Per-Crawl answers crawlers with
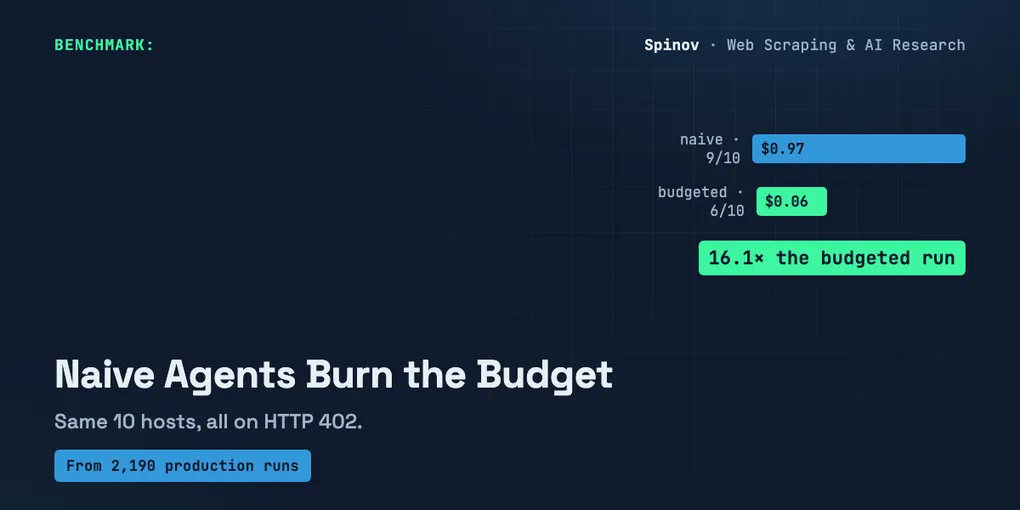
HTTP 402 Payment Requiredplus acrawler-priceheader. To pay, the crawler re-requests withcrawler-exact-priceand expects200. (Cloudflare, 2025-07-01) - On a synthetic 10-host fixture (prices I made up to exercise every branch), a naive agent that treats
402like “just pay and move on” spent $0.9658 against a $0.10 budget — roughly 10x over budget, or 16x what the budgeted agent spent ($0.0600). Same numbers, two different baselines; I keep them straight below. It fetched 9 of 10 pages. - A 40-line handler that branches three ways (free API fallback / price cap / skip+log) spent $0.0600, stayed under budget — and got 6 of 10 pages. The cap costs you reach, not money you can’t see.
- This is the same 200/403/429 decision tree I’ve run across 2,190 production runs.
402is a new leaf on it. The only difference is the dollar sign on the end. - The code below is stdlib-only, deterministic, no network. Copy it, run it, change the prices.
What actually changed
For most of HTTP’s life, 402 was a placeholder. RFC 9110, §15.5.3, says it in full: “The 402 (Payment Required) status code is reserved for future use.” (RFC 9110). That’s the entire section. A status code that sat empty for decades.
Pay-Per-Crawl is the first time I’ve seen it wired into production at scale. The flow is plain. A crawler asks for a page. Instead of 200 or 403, the origin returns 402 with a header — crawler-price: USD XX.XX. If the crawler wants the content, it asks again, this time carrying crawler-exact-price to agree to the charge, and the origin serves 200. There’s a proactive variant too, where the crawler leads with crawler-max-price on the first request. All of that is in Cloudflare’s own announcement.
Stack Overflow and Cloudflare publicly ran a pay-per-crawl arrangement on Stack Overflow’s data earlier this year, which is worth reading if you want the publisher’s side of the deal. (I’ll be honest about what I won’t quote: a few aggregator posts floating around cite specific “−32% bot traffic / +27% revenue” pilot numbers. I went to the official Stack Overflow blog to confirm them and they aren’t there. So I’m leaving them out. The argument doesn’t need them.)
Here’s the contrarian bit, and the reason this matters to anyone writing a fetcher. The “robots.txt is dead” takes are aimed at the wrong layer. Enforcement didn’t disappear — it moved from a polite text file the server hopes you read, down to the network edge, where it’s a real response with a real price. For a crawler that used to ask “am I allowed?”, the question quietly became “how much?”. And “how much” is a runtime policy decision, not a parsing problem. Your client library doesn’t make policy decisions. You do.
The tree I already run, and where 402 plugs in
I’ll put the original number on the table, because it’s the only reason I have anything to add here. Across my published Apify actors I’ve logged 2,190 production runs lifetime — real jobs against real sites, not tutorial demos. The Trustpilot review scraper alone accounts for 962 of them. That’s not a vanity stat; it’s where the branch tree comes from.
Every one of those runs lives inside a decision tree keyed on the HTTP response:
200→ parse it.403→ hard block. Back off, rotate identity, or skip and log. Old-world enforcement.429→ rate limited. Back off with jitter, retry later.
That tree has a property worth naming out loud: every branch is free. Wrong, sure — a 403 storm costs you wall-clock time and burned proxies. But it never debits an account. The worst a 429 does is make you wait.
402 breaks that property. It’s a new leaf on the exact same tree, and structurally it sits right next to 403 — both are “the door is not simply open.” But where 403 says no, 402 says not for free. That single difference forces three decisions your default HTTP client was never built to make:
- Is there a free or cheaper source for this host? A keyless API, a sitemap, a public dump. If yes, route there. $0.
- Is this single page worth its asking price? You need a per-page ceiling, or one expensive page quietly eats the run.
- Can I still afford it? A per-run budget that decrements as you spend, so the 50th
402can’t spend money the 5th already committed.
None of those three live in requests or httpx. They’re policy. And on 402, policy is the whole ballgame.
Quick gut-check before the code, because I want you to feel why this isn’t theoretical. The Trustpilot scraper ran 962 times. Imagine those targets sat behind Pay-Per-Crawl at a trivial $0.001 a page. At a few hundred pages per run, that’s a real, recurring line item — pennies that compound into a number you’d put on an invoice. A naive “pay and move on” agent wouldn’t even flinch. It’d just spend.
The handler
Here’s the whole thing. Stdlib only, no network, deterministic — so the output you see is the output you’ll get. The “network” is a fixture: ten hosts, each with how it responds, its price if it returns 402, and whether a free API exists for it.
Code maturity: toy/illustrative. This models the decision logic, not the wire protocol. Read the “what’s faked” section after it before you ship anything near it.
#!/usr/bin/env python3
"""
HTTP 402 Payment Required handler for an autonomous fetch agent.
Deterministic, stdlib-only, no network. Simulates the Cloudflare Pay-Per-Crawl
flow: a page can answer 200 (free), 403 (hard block), or 402 + crawler-price
(paid). The agent decides per-page using a per-run price budget.
Policy on 402:
1. paid-fetch : price <= remaining budget AND <= per-page cap -> pay, re-request, expect 200
2. api-fallback: a keyless/cheaper data source exists for this host -> use it, $0
3. skip+log : price too high / no budget -> do NOT pay, record decision, move on
Mirrors the 403/429 branch tree we already run in production (2,190 runs):
402 is just a new leaf with a price attached.
"""
# --- fixture: deterministic "network". Each entry = how a host responds to a crawl.
# status: what the origin returns on first crawl. price: USD per fetch if 402.
# has_api: a keyless/cheaper structured source exists for this host.
PAGES = [
# host, status, price, has_api
("docs.example.com", 402, 0.0008, True), # cheap + api -> api wins (free)
("news.example.org", 402, 0.02, False), # mid price, no api -> pay if budget
("shop.example.net", 402, 0.25, False), # expensive, no api -> over per-page cap -> skip
("blog.example.io", 200, 0.0, False), # free, just fetch
("wiki.example.com", 402, 0.005, True), # cheap, api exists -> api (free)
("paywall.example.co", 402, 0.50, False), # very expensive -> skip
("feed.example.org", 402, 0.01, False), # mid, no api -> pay
("legacy.example.biz", 403, 0.0, False), # hard block (old-world) -> skip+log
("data.example.ai", 402, 0.03, False), # mid, no api -> pay
("store.example.dev", 402, 0.15, False), # > per-page cap -> skip
]
PER_PAGE_CAP = 0.05 # never pay more than 5 cents for a single page
RUN_BUDGET = 0.10 # total we are willing to spend this run
def crawl(host, status, price, has_api, budget_left):
"""Returns (verdict, cost, served_status). Pure function of inputs + budget_left."""
if status == 200:
return ("FETCH_FREE", 0.0, 200)
if status == 403:
return ("SKIP_BLOCKED", 0.0, 403)
if status == 402:
# 1. prefer a free/cheaper structured source
if has_api:
return ("API_FALLBACK", 0.0, 200)
# 2. refuse if a single page costs more than the cap
if price > PER_PAGE_CAP:
return ("SKIP_TOO_EXPENSIVE", 0.0, 402)
# 3. refuse if it would blow the run budget
if price > budget_left:
return ("SKIP_NO_BUDGET", 0.0, 402)
# 4. pay, re-request with payment header, expect 200
return ("PAID_FETCH", price, 200)
return ("SKIP_UNKNOWN", 0.0, status)
def run(pages, naive=False):
spent = 0.0
got_content = 0
paid_count = 0
rows = []
for host, status, price, has_api in pages:
if naive:
# naive agent: treats 402 like "just pay and move on", no cap, no api,
# no budget check -- the mistake we want to show.
if status == 402:
verdict, cost, served = ("PAID_FETCH", price, 200)
elif status == 200:
verdict, cost, served = ("FETCH_FREE", 0.0, 200)
else:
verdict, cost, served = ("SKIP_BLOCKED", 0.0, status)
else:
verdict, cost, served = crawl(host, status, price, has_api, RUN_BUDGET - spent)
spent += cost
if served == 200:
got_content += 1
if verdict == "PAID_FETCH":
paid_count += 1
rows.append((host, status, f"${price:.4f}", verdict, f"${cost:.4f}", served))
return spent, got_content, paid_count, rows
def show(title, pages, naive):
spent, got, paid, rows = run(pages, naive=naive)
print(f"=== {title} ===")
print(f"{'host':<22}{'orig':>5}{'price':>10} {'decision':<19}{'paid':>9}{'served':>8}")
for host, status, price, verdict, cost, served in rows:
print(f"{host:<22}{status:>5}{price:>10} {verdict:<19}{cost:>9}{served:>8}")
print(f"-> content pages: {got}/{len(pages)} paid fetches: {paid} SPENT: ${spent:.4f} (budget ${RUN_BUDGET:.2f})")
print()
return spent, got
if __name__ == "__main__":
print(f"per-page cap=${PER_PAGE_CAP:.2f} run budget=${RUN_BUDGET:.2f} pages={len(PAGES)}\n")
naive_spent, naive_got = show("NAIVE agent (pays every 402, no cap/api/budget)", PAGES, naive=True)
gated_spent, gated_got = show("BUDGETED agent (api-fallback / cap / skip+log)", PAGES, naive=False)
overspend = naive_spent - gated_spent
print(f"NAIVE spent ${naive_spent:.4f} for {naive_got} pages | BUDGETED spent ${gated_spent:.4f} for {gated_got} pages")
print(f"Budgeted agent paid ${gated_spent:.4f} and stayed under the ${RUN_BUDGET:.2f} run budget; naive overspent by ${overspend:.4f} ({naive_spent/gated_spent:.1f}x) and blew the budget.")
assert naive_spent > RUN_BUDGET, "naive should blow the budget"
assert gated_spent <= RUN_BUDGET, "budgeted must respect the budget"
# honest trade-off: the budgeted agent buys FEWER pages on purpose --
# it refuses the expensive ones instead of silently draining the wallet.
skipped = naive_got - gated_got
print(f"Trade-off: budgeted skipped {skipped} expensive page(s) it refused to pay for. "
f"That is the point -- a price ceiling costs you reach, not money you can't see.")
assert gated_got <= naive_got, "budgeted trades reach for cost control (expected)"
print("All asserts passed.")Run it yourself: python3 -I agent_402_handler.py. No flags, no deps.
The output
This is the real stdout, copy-pasted, not paraphrased:
per-page cap=$0.05 run budget=$0.10 pages=10
=== NAIVE agent (pays every 402, no cap/api/budget) ===
host orig price decision paid served
docs.example.com 402 $0.0008 PAID_FETCH $0.0008 200
news.example.org 402 $0.0200 PAID_FETCH $0.0200 200
shop.example.net 402 $0.2500 PAID_FETCH $0.2500 200
blog.example.io 200 $0.0000 FETCH_FREE $0.0000 200
wiki.example.com 402 $0.0050 PAID_FETCH $0.0050 200
paywall.example.co 402 $0.5000 PAID_FETCH $0.5000 200
feed.example.org 402 $0.0100 PAID_FETCH $0.0100 200
legacy.example.biz 403 $0.0000 SKIP_BLOCKED $0.0000 403
data.example.ai 402 $0.0300 PAID_FETCH $0.0300 200
store.example.dev 402 $0.1500 PAID_FETCH $0.1500 200
-> content pages: 9/10 paid fetches: 8 SPENT: $0.9658 (budget $0.10)
=== BUDGETED agent (api-fallback / cap / skip+log) ===
host orig price decision paid served
docs.example.com 402 $0.0008 API_FALLBACK $0.0000 200
news.example.org 402 $0.0200 PAID_FETCH $0.0200 200
shop.example.net 402 $0.2500 SKIP_TOO_EXPENSIVE $0.0000 402
blog.example.io 200 $0.0000 FETCH_FREE $0.0000 200
wiki.example.com 402 $0.0050 API_FALLBACK $0.0000 200
paywall.example.co 402 $0.5000 SKIP_TOO_EXPENSIVE $0.0000 402
feed.example.org 402 $0.0100 PAID_FETCH $0.0100 200
legacy.example.biz 403 $0.0000 SKIP_BLOCKED $0.0000 403
data.example.ai 402 $0.0300 PAID_FETCH $0.0300 200
store.example.dev 402 $0.1500 SKIP_TOO_EXPENSIVE $0.0000 402
-> content pages: 6/10 paid fetches: 3 SPENT: $0.0600 (budget $0.10)
NAIVE spent $0.9658 for 9 pages | BUDGETED spent $0.0600 for 6 pages
Budgeted agent paid $0.0600 and stayed under the $0.10 run budget; naive overspent by $0.9058 (16.1x) and blew the budget.
Trade-off: budgeted skipped 3 expensive page(s) it refused to pay for. That is the point -- a price ceiling costs you reach, not money you can't see.
All asserts passed.Read the naive block top to bottom. It pays for everything: a $0.0008 page, then a $0.25 page, then a $0.50 page, no hesitation, because nothing in its logic ever says no to a price. Final tally: $0.9658 on a $0.10 budget — about 10x over the budget itself, and $0.9058 more than the budgeted agent spent ($0.0600), which is the 16.1x ratio the script prints at the end. (Two baselines, one easy thing to garble, so I’m spelling both out: ~10x vs the budget, 16x vs the disciplined agent. All four figures are straight off the stdout above.) It got 9 of 10 pages — and that’s exactly the trap. It looks productive. The damage is in the column you only check when the bill arrives.
The budgeted block makes different calls on the same ten hosts. Two cheap pages had a free API, so it took the API and paid nothing. Three pages priced above the $0.05 per-page cap got refused outright — SKIP_TOO_EXPENSIVE, served 402, no money spent. It paid for three. Total: $0.0600, under budget.
The trade-off I’m not going to hide
The budgeted agent got 6 pages. The naive one got 9. Three fewer. That’s not a rounding error; it’s the deal.
The cap means you walk away from shop.example.net, paywall.example.co, and store.example.dev — pages you could have had, for money. Sometimes one of those is the page that mattered. A price ceiling buys cost control by spending reach. You feel that loss immediately, in the result count. You do not feel an overspend until the invoice. That asymmetry is the entire reason to set the policy before the run, not after the bill.
So the right frame on 402 isn’t “pay or get blocked.” It’s: decide, ahead of time, what a single page is worth to you, and what the whole run is worth to you. Then let the agent enforce both, coldly, on every leaf.
What’s faked, and what production actually needs
I’d rather you trust the argument than the demo, so here’s where the demo lies:
- The fixture isn’t a live Cloudflare endpoint. The prices, the
has_apiflags, the statuses — I made them up to exercise every branch. They’re illustrative. Real Pay-Per-Crawl prices are set per-publisher and read off thecrawler-priceheader on a live402, not from a Python list. - The budget is in-memory. Reset on every run. A production handler needs a durable budget counter — a row in Postgres, a Redis key, something that survives a crash mid-run. Otherwise a restart re-arms the full budget and you double-spend.
- There’s no real payment. No
crawler-exact-priceheader sent, no200actually returned, no money actually moved.PAID_FETCHis a label here. The real handler readscrawler-price, decides, re-requests with the agreement header, and reconciles what it was actually charged against what it expected. - Concurrency would break the naive budget check. Two workers reading
budget_leftat once can both think there’s room. A real per-run budget needs an atomic decrement.
So treat this as the shape of the policy, not a drop-in. The shape is the point: a free-source check, a per-page cap, a per-run budget, and a logged skip. Wire those into your fetch loop and the live protocol bits are mechanical.
Where I’d draw the line — and where I’m genuinely unsure
I’ll say what I’d ship and where I’d stop.
A per-page cap and a per-run budget, both hard, both durable: yes, day one. Free-source fallback before paying: yes, it’s the cheapest win in the list. Per-domain price tiers, where you’ll pay more for a domain you already know is high-value? I think that’s right. But I haven’t run it against real Pay-Per-Crawl prices, so I’m guessing at the tier boundaries. Call it ±a lot.
The one I keep going back and forth on: should an agent be allowed to pay autonomously at all? Letting code move money based on a header it didn’t fully verify is the kind of thing that’s fine 999 runs out of 1,000 and a disaster on the 1,000th. My instinct is a human-in-the-loop gate on the first 402 from any new domain, then autonomous within a per-domain ceiling after that. But I haven’t lived through a real overspend incident on this yet — Pay-Per-Crawl is new, and I want to be straight that I have zero production payment runs behind that opinion. The 2,190 runs taught me the branch tree. They didn’t teach me what it feels like when the leaf has a price.
So, real question, not a comment-bait one: where do you draw the line — a per-page cap, a per-run budget, or per-domain price tiers? And would you let an agent pay autonomously at all, or is a human-in-the-loop on the first 402 non-negotiable? If you’ve already shipped against Pay-Per-Crawl, I especially want to hear what broke.
I write about production scraping and what 2,190 real runs actually teach you — the failures, the costs, the branch trees the docs skip. Follow for the next batch of numbers, and drop your 402 policy in the comments. I read every one.
AI-disclosure: drafted with an AI writing assistant, edited by a human before publishing. The Python above is stdlib-only and was run on my machine (python3 -I); the output block is copied verbatim from stdout and the asserts pass deterministically. The $0.9658 / $0.0600 / 16.1x figures and the page counts are that script’s exact output; the 2,190 / 962 run counts are from my own Apify production history; external claims link to primary sources.
More production scraping tips: t.me/scraping_ai