Your RAG Answers Confidently. The Source Doesn't Say That.
The retrieval was perfect. The right document came back, top of the list, high similarity score. And the answer still quoted a price that wasn’t in it. The model took “40 pounds” from the chunk and confidently told the user “50 dollars on the US store.” There is no US store. There is no 50. Nobody saw the chunk. The pipeline logged a clean success.
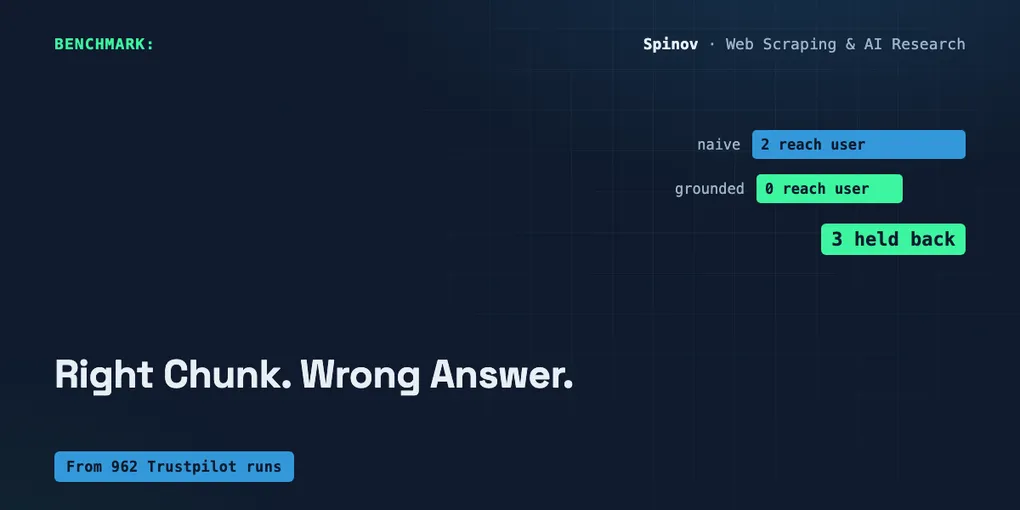
Your RAG can retrieve the right chunk and still answer with a fact that isn’t in it: a rounded number, a stitched-together inference, a quiet fallback to the model’s own memory. Retrieval metrics don’t see it. The fix runs after generation, before you answer. Check that each claim has textual support in the retrieved context, and hold back the ones that don’t. Below: a deterministic floor in ~35 lines of stdlib Python, with output.
Everyone is fixing retrieval. Almost nobody checks generation.
Look at where the RAG energy goes. Better chunking. Reranking. Hybrid search. Freshness and TTL. Metadata filters. Every one of those makes the retrieval better, so the right text comes back more often.
None of them check whether the answer actually used that text.
That’s the gap. You can have flawless retrieval and a wrong answer, because the failure happens one layer up: in generation, after the good chunks are already in the context window. The model has the right paragraph sitting right there and still says something the paragraph never said. Your recall@k looks great. Your faithfulness is broken. And the two metrics live in different parts of the stack, so the dashboard stays green.
I spend my days on the layer underneath this. I run scrapers in production: 2,190 runs across 32 published actors, the busiest being a Trustpilot review scraper at 962 runs. Those scrapers collect exactly the corpus that later gets chunked and fed to a RAG system. Reviews, prices, ratings, product blurbs. I’ve watched a “clean” extracted string disagree with the actual page enough times to write a whole post about it (your scraper got clean data, the site lied). The same gap reappears one floor up. The text in the chunk is right. The answer built on top of it is not.
What “answered, but not from the source” actually looks like
This isn’t one bug. It’s a family. Four members I keep seeing:
Right chunk, wrong number. Retrieval nailed the document. The model “rounds,” swaps a currency, or blends the figure with something it half-remembers from pretraining. The chunk says £40, the answer says $50. The shape is correct, so it reads as authoritative.
Cross-chunk synthesis. Fact A lives in chunk 1, fact B in chunk 2. The model draws conclusion C: plausible, tidy, and stated in neither chunk. “Best value 1.5-litre kettle under $50” is the kind of sentence that sounds sourced and is pure invention.
Empty context, full confidence. Retrieval came back thin or off-topic. Instead of saying “I don’t know,” the model falls back to parametric memory and serves general knowledge as if it came from your documents.
Citation without support. The answer ends in [doc 3]. Doc 3 does not contain that claim. The footnote is theater.
In every case the prose is fluent and certain. The user never sees the chunks. There’s no exception, no retry. From the pipeline’s point of view, it worked.
The fix: a grounding gate on the output
Here’s the move, and it’s almost embarrassingly simple. After the model generates, before you hand the answer to the user, split the answer into atomic claims (sentence-ish) and ask one question per claim: are the content tokens of this claim actually present in the retrieved context? If too few of them are, flag the claim UNSUPPORTED and hold it back. Cut it, or surface it with an explicit “not confirmed by source” marker. Don’t ship it as fact.
This is the same principle I’ve been applying to the input side of agents: validating a fetched body before reasoning over it (the garbage-200 post, linked below), checking the age of a chunk before trusting it (the freshness post). Same idea, new target. Now it’s the generated claim checked against the retrieved context.
One honest framing before the code, because it’s the whole point. Token overlap is a floor, not a ceiling. It catches fabricated concretes: numbers, names, and stitched-together facts that simply aren’t in the text. But it cuts both ways, and the second edge is the dangerous one. It does not understand meaning, so it punishes honest rewording. A RAG generator is supposed to paraphrase the source, not parrot it token for token. The moment it writes “gave 3 stars” where the chunk said “rated 3 stars,” lexical coverage drops and a perfectly grounded sentence gets flagged. That’s a false positive on correct behavior, and the demo below shows it happening live. It also stays blind to the opposite case: a claim that reuses the context’s words while flipping their sense sails right through. For both edges you need an NLI or LLM-judge layer on top. What this floor buys you is the cheapest, most deterministic first pass against the most common and most expensive failure I see in scraped corpora: invented specifics. And the reason I aim it at numbers and names first is that those are exactly the fields my Trustpilot runs taught me to verify character-by-character. A price. A star rating like “3 of 5 stars.” Those are what the model loves to make up on top of a real review.
The demo
stdlib only: re and json. No network, no randomness, no clock. Hardcoded synthetic fixtures: three “retrieved chunks” (a kettle’s price, a review, a spec) and a five-sentence model answer. Two sentences invent things. A third is correctly grounded but paraphrased — and watch what the floor does to it, because that’s the part you have to see before you trust this. It’s runnable local against synthetic fixtures. I’m not calling a real LLM or vector DB here, on purpose, so the output is identical every run. The grounding mechanism transfers 1:1 to a live pipeline: drop in your retrieved chunks and your model output.
"""
grounding_check.py — a deterministic token-overlap FLOOR for RAG output grounding.
What this is: a cheap, dependency-free first gate that runs AFTER generation and
BEFORE you return the answer. For each claim sentence it asks one question:
"are the content tokens of this claim actually present in the retrieved context?"
If not enough of them are, the claim is flagged UNSUPPORTED and held back.
What this is NOT: a hallucination detector. Token overlap catches FABRICATED
CONCRETES — numbers, names, and stitched-together facts that simply are not in
the text. It does NOT understand paraphrase or meaning. The flip side, and the
point of this demo: it FALSE-POSITIVES on honest paraphrase. A correctly
grounded claim that rewords the source (rated -> gave, said -> noted) loses
coverage and gets wrongly held back. A claim that reuses the context's words
while reversing their sense passes. For both you need an NLI or LLM-judge layer
ON TOP. This is the floor, not the ceiling.
Fixtures (retrieved chunks + model answer) are SYNTHETIC and hardcoded.
stdlib only (re, json). No network, no randomness, no clock. Deterministic:
the same stdout every run, so MD5(stdout) is stable for an integrity gate.
Run: python3 -I grounding_check.py
"""
import re
import json
# --- SYNTHETIC fixtures: what the retriever returned (assume retrieval was GOOD) ---
# Three short chunks. Think of them as a Trustpilot-style review card plus a spec.
RETRIEVED_CHUNKS = [
{
"id": "doc1",
"text": "The Acme Kettle is priced at 40 pounds on the official store. "
"It ships in a recyclable box.",
},
{
"id": "doc2",
"text": "This reviewer rated the Acme Kettle 3 of 5 stars. "
"They liked the design but said it descales slowly.",
},
{
"id": "doc3",
"text": "The Acme Kettle holds 1.5 litres and has a stainless steel base.",
},
]
# The full retrieved context the generator was handed.
CONTEXT = " ".join(c["text"] for c in RETRIEVED_CHUNKS)
# --- SYNTHETIC fixtures: what the LLM generated on top of that context ---
# Three of these are grounded; two invent concretes that are not in any chunk.
# Watch what the floor does to the THIRD grounded one (the paraphrase).
ANSWER_CLAIMS = [
# grounded, copies words: price 40 pounds is verbatim in doc1
"The Acme Kettle is priced at 40 pounds.",
# grounded BUT PARAPHRASED: doc2 says "rated... said", the answer says
# "gave... noted". Same fact, reworded. The floor will FALSE-POSITIVE here.
"One reviewer gave it 3 of 5 stars and noted it descales slowly.",
# UNSUPPORTED — fabricated number: nothing says 50 dollars
"On the US store the same kettle costs 50 dollars.",
# UNSUPPORTED — cross-chunk synthesis: 'best value 1.5 litre kettle' is a
# conclusion no single chunk states; it stitches price + capacity + rating.
"That makes it the best value 1.5 litre kettle under 50 dollars.",
# supported: capacity and stainless base are in doc3
"It holds 1.5 litres and has a stainless steel base.",
]
# Tiny stop list: REAL glue words only (articles, prepositions, pronouns,
# auxiliaries). No content verbs or nouns. Curating this list to make a demo
# pass is itself the trap this article is about — see the paraphrase claim.
STOP = {
"the", "a", "an", "is", "are", "it", "this", "that", "of", "on", "in",
"and", "to", "with", "at", "they", "them", "same",
}
WORD = re.compile(r"[a-z0-9]+")
def tokens(text):
"""lowercase content tokens, stop-words removed. pure function."""
return [t for t in WORD.findall(text.lower()) if t not in STOP]
def coverage(claim, context_tokens):
"""fraction of the claim's content tokens that appear in the context.
pure, deterministic. returns (ratio, missing_tokens)."""
ct = tokens(claim)
if not ct:
return 1.0, []
missing = [t for t in ct if t not in context_tokens]
present = len(ct) - len(missing)
return present / len(ct), missing
THRESHOLD = 0.75 # tune per corpus — see article. floor heuristic, not a law.
def naive_mode():
"""Ship everything the model said, no check. The default RAG pipeline."""
print("NAIVE MODE (no post-generation grounding check)")
for c in ANSWER_CLAIMS:
print(" SHIPPED AS FACT :", c)
shipped = len(ANSWER_CLAIMS)
print(f" -> {shipped} claims shipped as fact, "
f"unsupported ones reached the user")
return shipped
def grounded_mode():
"""Check each claim's token support against the retrieved context."""
ctx = set(tokens(CONTEXT))
print("GROUNDED MODE (token-overlap floor, threshold "
f"{THRESHOLD:.2f}, synthetic fixtures)")
supported, blocked, rows = 0, 0, []
for c in ANSWER_CLAIMS:
cov, missing = coverage(c, ctx)
ok = cov >= THRESHOLD
verdict = "SUPPORTED" if ok else "UNSUPPORTED"
if ok:
supported += 1
else:
blocked += 1
rows.append({"claim": c, "verdict": verdict,
"coverage": round(cov, 2), "missing": missing})
flag = "" if ok else " <-- held back"
print(f" [{cov:0.2f}] {verdict:<11} {c}{flag}")
if missing and not ok:
print(f" missing from context: {missing}")
print(f" -> supported={supported}, unsupported={blocked}, "
f"blocked_before_answer={blocked}")
return {"supported": supported, "blocked": blocked, "rows": rows}
def main():
naive_mode()
print()
result = grounded_mode()
print()
print("WHAT THE FLOOR DID (the good, the bad):")
print(" caught: a fabricated number (50 dollars) and a cross-chunk")
print(" synthesis ('best value...') that no chunk states.")
print(" FALSE-POSITIVE: an honest paraphrase ('gave/noted' for")
print(" 'rated/said') wrongly held back. correct behavior, punished.")
print(" blind to: reversed meaning that reuses the context's own words.")
print(" for both, add an NLI / LLM-judge layer on top. floor, not ceiling.")
print()
print("SUMMARY:", json.dumps(
{"naive_shipped_as_fact": len(ANSWER_CLAIMS),
"grounded_supported": result["supported"],
"grounded_blocked": result["blocked"]},
sort_keys=True))
if __name__ == "__main__":
main()Run it with python3 -I grounding_check.py and you get this, byte for byte:
NAIVE MODE (no post-generation grounding check)
SHIPPED AS FACT : The Acme Kettle is priced at 40 pounds.
SHIPPED AS FACT : One reviewer gave it 3 of 5 stars and noted it descales slowly.
SHIPPED AS FACT : On the US store the same kettle costs 50 dollars.
SHIPPED AS FACT : That makes it the best value 1.5 litre kettle under 50 dollars.
SHIPPED AS FACT : It holds 1.5 litres and has a stainless steel base.
-> 5 claims shipped as fact, unsupported ones reached the user
GROUNDED MODE (token-overlap floor, threshold 0.75, synthetic fixtures)
[1.00] SUPPORTED The Acme Kettle is priced at 40 pounds.
[0.67] UNSUPPORTED One reviewer gave it 3 of 5 stars and noted it descales slowly. <-- held back
missing from context: ['one', 'gave', 'noted']
[0.33] UNSUPPORTED On the US store the same kettle costs 50 dollars. <-- held back
missing from context: ['us', 'costs', '50', 'dollars']
[0.30] UNSUPPORTED That makes it the best value 1.5 litre kettle under 50 dollars. <-- held back
missing from context: ['makes', 'best', 'value', 'litre', 'under', '50', 'dollars']
[1.00] SUPPORTED It holds 1.5 litres and has a stainless steel base.
-> supported=2, unsupported=3, blocked_before_answer=3
WHAT THE FLOOR DID (the good, the bad):
caught: a fabricated number (50 dollars) and a cross-chunk
synthesis ('best value...') that no chunk states.
FALSE-POSITIVE: an honest paraphrase ('gave/noted' for
'rated/said') wrongly held back. correct behavior, punished.
blind to: reversed meaning that reuses the context's own words.
for both, add an NLI / LLM-judge layer on top. floor, not ceiling.
SUMMARY: {"grounded_blocked": 3, "grounded_supported": 2, "naive_shipped_as_fact": 5}Read the grounded block top to bottom, because the interesting result is not the two it caught. Naive mode ships all five sentences as fact, so the invented “$50” and the “best value” conclusion reach the user. Grounded mode holds those two back: look at the missing from context line, that’s the gate showing its work. The tokens 50, dollars, us don’t exist in any chunk, coverage falls to 0.33, held back. Good.
Now the awkward one. The review sentence, “One reviewer gave it 3 of 5 stars and noted it descales slowly,” is true. The chunk says the reviewer rated it 3 of 5 stars and said it descales slowly. The model reworded “rated” to “gave” and “said” to “noted,” which is exactly what a generator should do. The floor doesn’t see synonyms. It sees three content tokens (one, gave, noted) that aren’t literally in the context, coverage drops to 0.67, and a correct claim gets held back. That’s a false positive on grounded output. Two sentences pass, three are flagged, and one of the three flags is wrong. That single row is the whole reason this is a floor you tune and not a gate you trust.
Read the failure modes honestly, because they decide whether you ship this
You already saw one failure in the output. Here’s the full list, in the order that matters before you trust a single block:
False positives on honest paraphrase. This is the one that decides everything. It’s not a corner case, it’s the floor fighting its own job. The whole reason you run a generator instead of returning raw chunks is to reword the source: synonyms, normalized units, resolved pronouns, merged sentences. Every one of those rewrites costs lexical coverage. The “gave 3 stars” row above is the small version; in production it’s “the device draws 5 amps” flagged because the chunk wrote “current: 5 A,” or “the warranty lasts two years” flagged because the spec said “24-month warranty.” Token overlap penalizes correct behavior, and the better your model paraphrases, the more grounded answers it wrongly blocks. That is why this is a pre-filter, not a verdict: anything it flags has to fall through to an NLI or LLM-judge that can see meaning, never straight to “deleted.”
The THRESHOLD = 0.75 is the open question, not a constant I’d defend. It’s the dial between the two errors above: set it low and fabricated claims slip through; set it high and more honest paraphrases get flagged. The right value depends on your corpus, your chunk size, and your tolerance for false flags. I’d start around 0.7–0.8 and tune against a labelled set, not vibes. There’s no universal number here and I’m not going to pretend there is.
The stop list is hand-rolled and tiny, and it’s the other half of the paraphrase problem. It holds real glue words only: articles, prepositions, pronouns. I deliberately did not stuff content verbs like “gave” or “noted” into it, because hiding the paraphrase miss behind a fattened stop list is exactly how you build a demo that lies. In a real corpus you’d want lemmatization (so “litre” matches “litres” instead of missing it; you can see that exact edge in the synthesis claim above) and a vetted stopword set, knowing it shifts but never removes the false-positive line.
The fixtures are synthetic. I wrote the chunks and the answer to show all three behaviors cleanly: a verbatim hit, two fabrications caught, one grounded paraphrase wrongly flagged. They are not a logged incident, and I’m labelling them as invented on purpose. The £40 and “3 of 5 stars” are styled after real Trustpilot fields I scrape, but the kettle and its “$50 US store” are make-believe so the demo stays deterministic and offline.
And the recap: this is a floor. It catches invented concretes, it false-positives on honest rewording, and it’s blind to a paraphrase that means the opposite. A grounding gate is not a replacement for an eval suite. It’s a cheap last check on the way out the door. Stack an NLI model or an LLM judge on top when correctness matters more than latency and cost.
Where this sits in the stack
The term comes from the original RAG paper: Lewis et al., 2020, “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks” (arXiv:2005.11401), which couples a retriever with a generator. The whole architecture assumes the generator stays anchored to what was retrieved. Nothing in it forces that to be true at inference time. That’s the slack this gate tightens.
The property you’re measuring has a name in RAG evaluation: faithfulness, or groundedness. The Ragas docs define faithfulness as the answer being “factually consistent with the given context,” scored by how many of the answer’s claims can be inferred from the retrieved context (docs.ragas.io). My floor is the dumbest possible approximation of that idea, lexical presence instead of inference, but it runs in microseconds with zero dependencies. That’s exactly what you want as a first gate before you spend tokens on a judge.
Two of my own posts are the input-side siblings of this one. In “AI agent trusts a 200 OK, the page was garbage” I validate the fetched body before any reasoning. In “AI agent memory has no expiry date” I check the age of a chunk before trusting it. Freshness is “the fact got old.” Grounding is “the fact was never there.” Different failure, same discipline: don’t trust the layer above without a cheap check on the layer below.
What to do Monday
Add one function between generation and response. Split the answer into claims, run each against the union of your retrieved chunks, and route anything under your tuned threshold somewhere it can be checked. Don’t drop it on the floor. Log every flagged claim. That log is the most useful RAG-quality signal you’re not currently collecting: it’s a mix of what your model invents on top of good context and what it just reworded too freely, and both are worth seeing. Then, when you have the budget, send the flagged set to an NLI or judge pass that can tell those two apart, and keep the lexical floor as the fast pre-filter that decides what’s even worth judging.
You don’t need a new framework for this. You need ~35 lines and the decision to look at generation instead of only retrieval.
I write about production scraping and the reliability layer under AI agents: real runs, real failures, real code. Follow for the next teardown, and tell me in the comments: what’s the worst “confidently wrong from a perfect chunk” answer your RAG has shipped? I read every one.
Proof, if you want it: a Trustpilot scraper I’ve run 962 times in production, at apify.com/knotless_cadence.